
In this demonstration, we will use a variable instead of a fixed JQL query. That way the data source will be reusable for different JQL queries and it is not necessary to copy the data source multiple times. This approach will also work for other Data Source types.
Prerequisites:
-
A data source that supports variables. In this example: Local Jira using the expression endpoint
Steps:
-
We create a local Jira data source configuration with the POST body using the expression endpoint with a fixed JQL first.
.../rest/api/3/expression/evaluate
{
"expression": "issues.map(i => {
id: i.id, key: i.key, summary: i.summary, description: i.description
})",
"context": {
"issues": {
"jql": {
"query": "assignee = EMPTY ORDER BY created DESC",
"maxResults": 50
}
}
}
}
We are using the fixed JQL query assignee = EMPTY ORDER BY created DESC which will return a specific set of work items.
-
The next step is to utilize a variable to dynamically create queries. In this example we replace the JQL query
asignee = EMPTY ORDER BY created DESCwith{jql}.
This is how the post body in our example should now look like:
{
"expression": "issues.map(i => {
id: i.id, key: i.key, summary: i.summary, description: i.description
})",
"context": {
"issues": {
"jql": {
"query": "{jql}",
"maxResults": 50
}
}
}
}
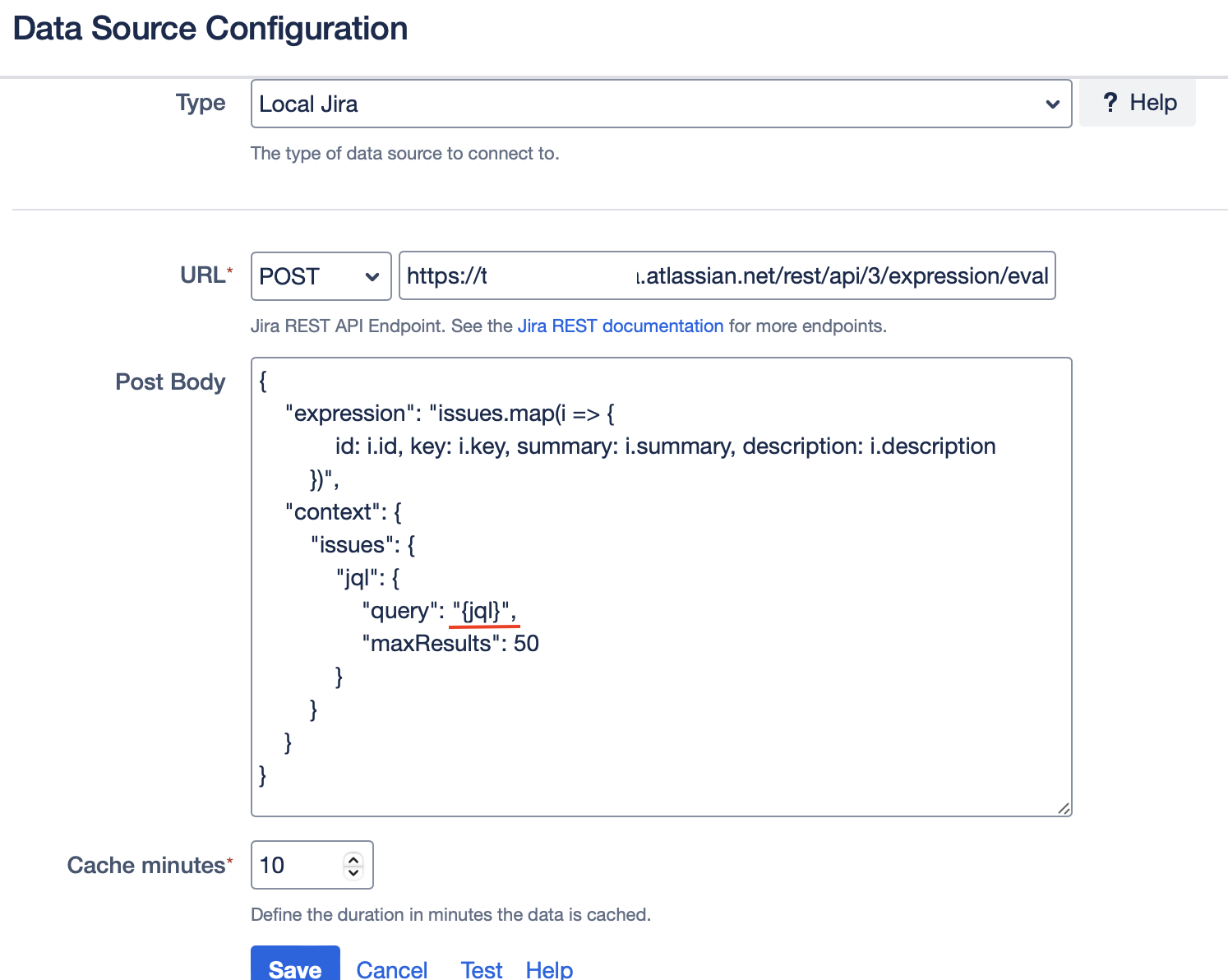
-
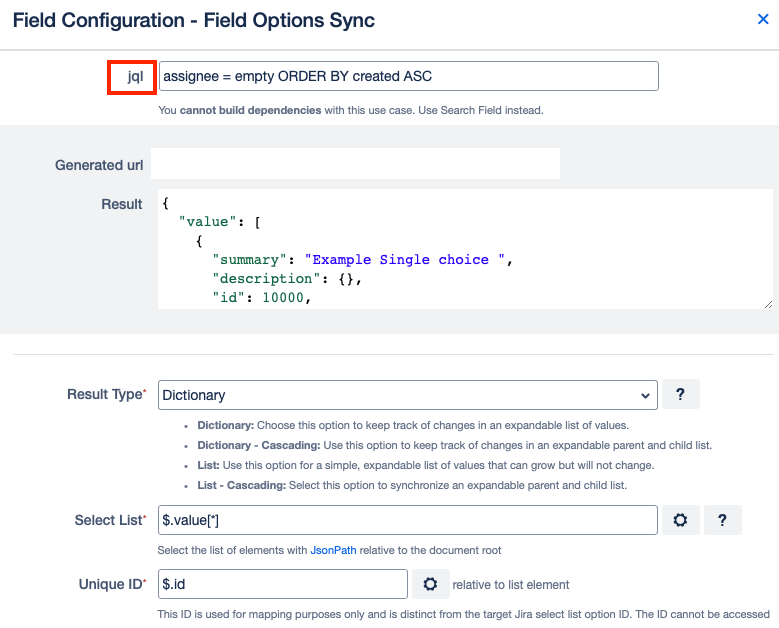
Now you can use this Data Source in multiple Field Configurations with different JQL queries. In this example we use Field Options Sync and entered the previously used JQL here instead.
Here is the result of the Field Configuration used in the work item to identify which work items have an empty Assignee field.
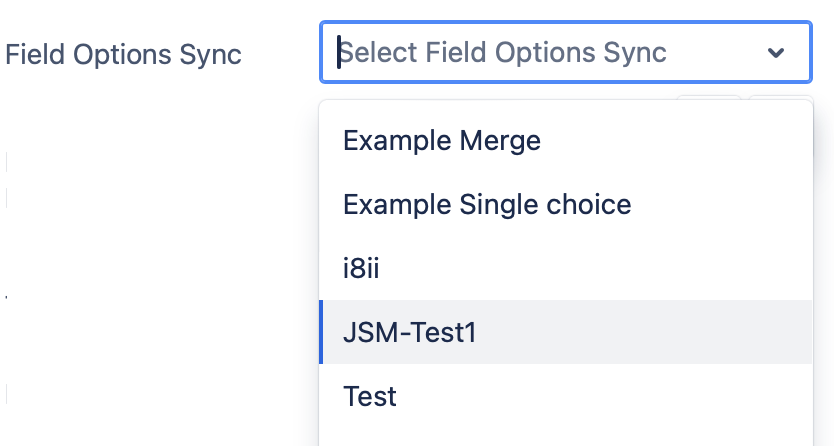
In a similar manner, we can use various Field Configurations and use different JQL queries to fetch the information and make our Data Source flexible.
